Обратите внимание, что шаги 3 и 4 являются действиями RDD, т.е. они возвращают результат драйверу, в данном случае Java int. Также помните, что Spark ленив и отказывается выполнять свою работу, пока не увидит действие. В этом случае никаких действий не предпринимается до шага 3.
Apache Spark
Материалы из Национальной библиотеки им. Н.Э. Бауман Последнее редактирование этой страницы: 18:19, 30 января 2019 г.
Apache Spark| Создатель: | Матей Захариас |
|---|---|
| Разработчики: | Apache Software Foundation |
| Выпущено: | 30 мая 2014 ; Матей: Матехи, Матехия, Матехия, Матехия, Матехия. 8 лет назад ( 2014-05-30 ). |
| Постоянное освобождение: | 2.4.0 / ноябрь 2018 ; 3 года назад ( 2018-11 ) |
| Статус разработки: | Активный |
| Написано в: | Scala, Java, Python и R |
| Операционная система: | Microsoft Windows, Linux, macOS |
| Платформа: | Виртуальная машина Java. |
| Размер распределения: | 217 МБ. |
| Лицензия: | Лицензия Apache 2.0. |
| Сайт | spark .apache .org |
Apache Spark — это фреймворк с открытым исходным кодом для реализации распределенной обработки неструктурированных и слабоструктурированных данных, который является частью экосистемы проекта Apache Hadoop. В отличие от классического оператора ядра Apache Hadoop, реализующего двухэтапную концепцию MapReduce с дисковым хранилищем, Spark использует специальные протоколы для обработки рекурсий в памяти, что приводит к значительному увеличению скорости для определенных классов задач5. В частности, возможность многократного доступа к пользовательским данным, загруженным в память, делает библиотеку привлекательной для алгоритмов машинного обучения.
Проект предоставляет интерфейсы программирования для Java, Scala, Python и R. Первоначально написанный на Scala, значительный объем кода на Java был позже добавлен, чтобы обеспечить возможность написания программ непосредственно на Java. Он состоит из ядра и нескольких расширений, таких как Spark SQL (позволяет выполнять SQL-запросы к данным), Spark Streaming (плагин для обработки потоковых данных), Spark MLlib (набор библиотек машинного обучения), GraphX (для обработки распределенных графов). Он может работать в кластерной среде Apache Hadoop под YARN или без основных компонентов Apache Hadoop и поддерживает различные распределенные системы хранения данных — HDFS, OpenStack Swift, NoSQL СУБД Cassandra, Amazon S3.
Ведущий автор, Матей Захария, румынско-канадский компьютерщик, начал работать над проектом в 2009 году, будучи аспирантом Калифорнийского университета в Беркли. Проект был выпущен под лицензией BSD в 2010 году, в 2013 году перешел в Apache Foundation и был помещен под лицензию Apache 2.0; в 2014 году он был включен как проект верхнего уровня Apache. Источник 1 .
Содержание
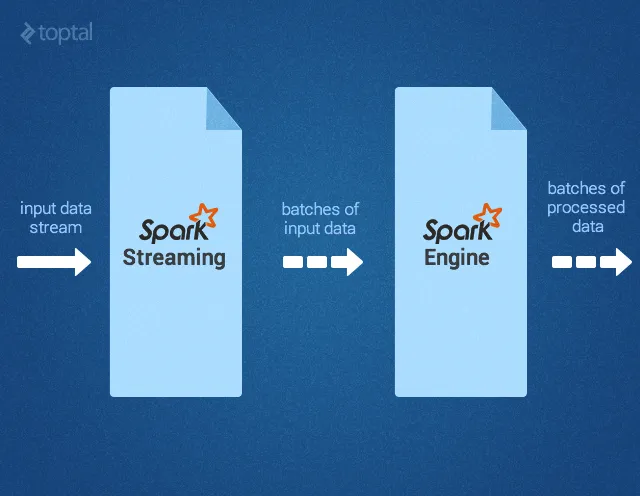
Рисунок 1 — Компоненты Spark Apache
SparkSQL — это компонент Spark, который поддерживает запросы к данным с использованием SQL или языка запросов Hive. Библиотека возникла как порт Apache Hive для работы на Spark (вместо MapReduce) и теперь интегрирована в стек Spark. Он не только обеспечивает поддержку нескольких источников данных, но и позволяет вложить SQL-запросы с преобразованиями кода — очень мощный инструмент.
Spark Streaming поддерживает потоковые данные в реальном времени, которыми могут быть журналы с работающего веб-сервера (например, Apache Flume и HDFS/S3), информация из социальных сетей, таких как Twitter, и различные очереди новостей, такие как Kafka. «Под капотом» Spark Streaming принимает потоки входных данных и разбивает их на пакеты. Затем эти данные обрабатываются механизмом Spark, после чего создается конечный поток данных (также в виде пакетов).
MLlib — это библиотека машинного обучения, которая предоставляет несколько алгоритмов для горизонтального масштабирования в кластере для классификации, регрессии, кластеризации, коллаборативной фильтрации и т.д. Некоторые из этих алгоритмов также работают с потоковыми данными — например, линейная регрессия по методу обыкновенных наименьших квадратов или кластеризация по методу k-means (список скоро будет расширен). Apache Mahout (библиотека машинного обучения для Apache Hadoop) уже покинула MapReduce и теперь разрабатывается совместно со Spark MLlib.
GraphX — это библиотека для обработки и выполнения параллельных операций над графами. Он предоставляет гибкий инструмент для ETL, исследовательского анализа и итеративных вычислений графов. В дополнение к встроенным функциям работы с графами предоставляется библиотека обычных графовых алгоритмов, таких как PageRank.
Начало работы со Spark
Лучше всего устанавливать дистрибутив на Unix-подобную систему, но здесь мы покажем, как установить его на Windows 10.
В видеоролике выше объясняется, как установить Spark на Windows. Следуйте приведенным ниже инструкциям.
- Вы можете загрузить и установить Gnu on Windows (GOW) по ссылке ниже. С помощью GOW вы можете использовать команды Linux в Windows. Для этой установки нам понадобятся curl, gzip и tar, которые предоставляет GOW.
- Загрузите и установите Anaconda для Windows.
- Откройте новую командную строку (CMD).
- Зайдите на сайт Apache Spark.
- Выберите версию Spark.
- Выберите тип пакета.
- Выберите тип загрузки: (Прямая загрузка).
- Скачать Spark. Помните, что если вы загрузите более новую версию, вам нужно будет изменить другие команды для загруженного файла.
- Загрузите файл winutils.exe по адресу spark-2.4.0-bin-hadoop2.7\bin и введите следующую команду в CMD.
- Убедитесь, что на вашем компьютере установлена Java 7+.
- Затем мы отредактируем переменные окружения, чтобы можно было открыть блокнот Spark в любом каталоге.
- Закройте свой терминал и откройте новый. Введите следующую команду.
Параметр —master указывает URL-адрес мастера для распределенного кластера, для локального запуска с одним потоком или N для локального запуска с N потоками. Вы должны начать локально с одного потока для тестирования.
- Если после ввода этой команды вы будете перенаправлены в браузер, то установка прошла успешно, и вы можете использовать Apache Spark.
Для этого просто введите в командной строке:
Вы должны получить ответ:
В зависимости от того, какую версию Spark вы выбрали в шаге 4, у вас может быть другая версия.
Любая организация или компания может проверить себя в качестве контрагента в СПАРК. Все, что вам нужно, — это доступ к официальному сайту Spark для проверки контрагента.
Встречайте фреймворк Spark

Spark — это платформа для кластерных вычислений и обработки больших данных. Spark предоставляет набор библиотек на трех языках (Java, Scala, Python) для унифицированного вычислительного механизма. Что это значит на самом деле?
Консолидация: Spark не нужно создавать приложение из нескольких API или систем. Spark предоставляет встроенные API для выполнения этой задачи.
Вычислительный движок: Spark поддерживает загрузку данных из различных файловых систем и выполнение вычислений на этих данных, но не хранит данные постоянно. Spark работает исключительно в памяти, обеспечивая беспрецедентную производительность и скорость.
Библиотеки: Фреймворк Spark состоит из набора библиотек, предназначенных для решения проблем науки о данных. Spark включает библиотеки для SQL (SparkSQL), машинного обучения (MLlib), обработки потоков (Spark Streaming и Structured Streaming) и обработки графов (GraphX).
Приложение Spark
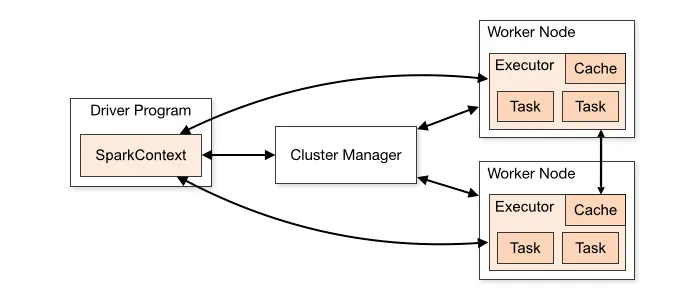
Каждое приложение Spark состоит из драйвера и набора распределенных рабочих процессов (исполнителей).
Драйвер запускает метод main() нашего приложения. Это создает SparkContext, за который отвечает драйвер Spark:
- Запускает задачу на узле нашего кластера или на клиенте и планирует ее выполнение с помощью менеджера кластера.
- Реагирует на расписание или ввод пользователя.
- Анализирует, планирует и распределяет задачи между исполнителями.
- Хранит метаданные о выполненном приложении и отображает их на веб-интерфейсе
Spark Executors
Исполнитель — это распределенный процесс, отвечающий за выполнение задач. Каждое приложение Spark имеет свой собственный набор исполнителей. Они выполняются в течение жизненного цикла одного приложения Spark.
- Исполнители выполняют всю обработку данных в заданиях Spark.
- Они хранят результаты в памяти и помещают их на диск только тогда, когда это указано в драйвере (Driver).
- По окончании работы он возвращает результаты водителю.
- Каждый узел может иметь от 1 исполнителя на узел до 1 исполнителя на ядро.